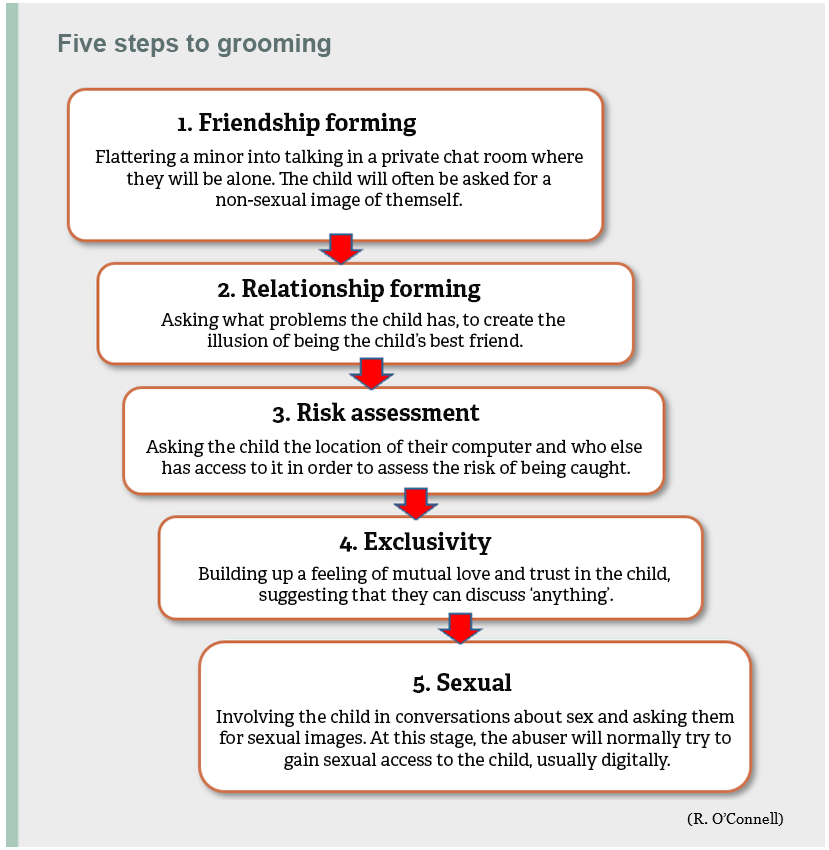
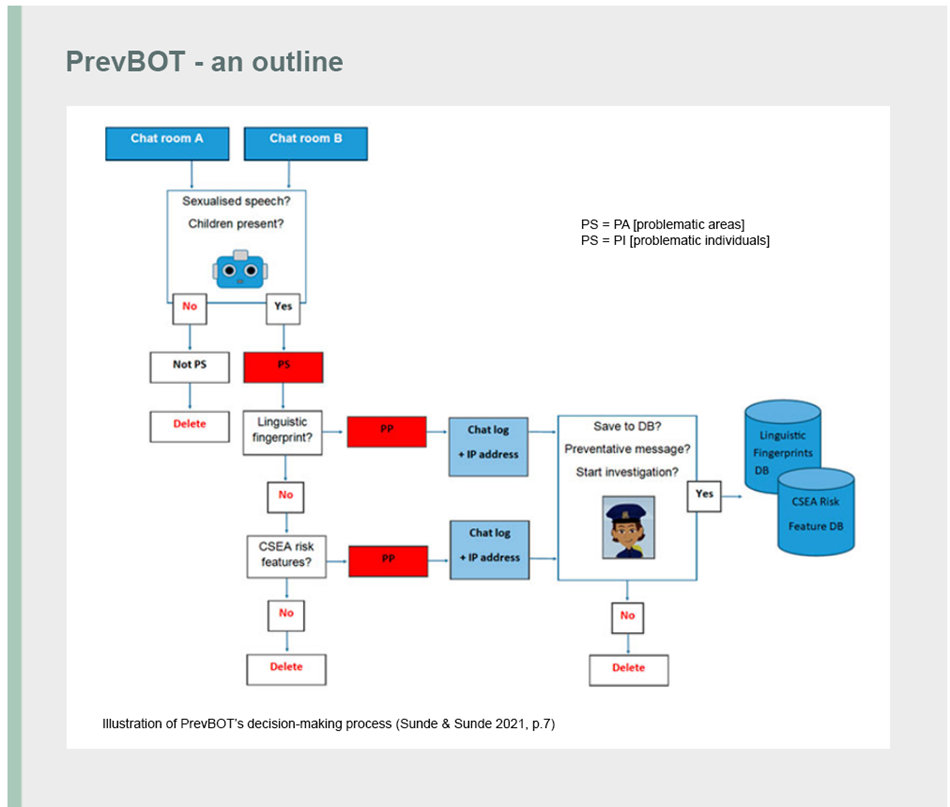
What is research?
Recital 159 of the GDPR sets out that ‘Where personal data are processed for scientific research purposes, this Regulation should also apply to that processing’. Since PrevBOT is a research project, personal data is processed for research purposes. It must first be considered whether the development of PrevBOT falls under the definition of research in the GDPR. This is because the processing of personal data for research purposes is in a special position in the GDPR, where there are certain exceptions to the general rules.
There is no universal and accepted definition of the term ‘scientific research’. Nor is the term defined in the GDPR or the Personal Data Act.
The OECD’s definition of research
The OECD has established the following international guidelines for the delimitation and classification of research:
Research and experimental development (R&D) comprise creative and systematic work undertaken in order to increase the stock of knowledge – including knowledge of humankind, culture and society – and to devise new applications of available knowledge.
Retrieved from the Frascati Manual 2015 (p. 28)
According to Recital 159 of the GDPR, the term ‘scientific research’ is to be interpreted broadly and may include, for example, technological development and demonstration, basic research and applied research. It should be mentioned that the European Data Protection Board (EDPB) is currently working on guidelines for the processing of personal data for scientific purposes, which is expected to provide an overview and an interpretation of the various provisions governing research in the GDPR.
PrevBOT is organised as a research project
The PrevBOT project is led by the Norwegian Police University College (PHS). In addition to being the central educational institution for police education, the PHS also offers continuing and further education, a master’s degree programme and research in police science. As mentioned in the introduction, the PrevBOT project is organised as a research project. The scope of the project is set out in the project memo the PHS submitted to the Ministry of Justice and Public Security.
The Data Protection Authority has not made an independent assessment of whether the processing activities in the PrevBOT project constitute processing of personal data for research purposes, but assumes that the actual development of PrevBOT by the PHS is to be considered ‘scientific research’ pursuant to the GDPR.
Difference between development (research) and use of PrevBOT
The Data Protection Authority emphasises that there is a difference between the processing of personal data for research into the development of artificial intelligence and the use of PrevBOT. The actual use of PrevBOT clearly falls outside the research definition. In the view of the Data Protection Authority, the continued learning of an algorithm in widespread use cannot be considered scientific research. It is therefore important that those responsible for the PrevBOT project are aware of the distinction between research and use, so that they do not rely on the research track in the data protection regulations with respect to the use and continued learning of the solution.
The data controller in a research project
The data controller is responsible for compliance with the data protection principles and regulations under the GDPR, and determines the purpose of the processing of personal data and the means to be used, cf. the GDPR Article 4(7). There may be one or more data controllers (either joint or separate) in a research project, and the data controller must, among other things, ensure that there is a basis for processing.
The PrevBOT project consists of several work packages involving different actors, and it is important that the data controller(s) are identified. In the Data Protection Authority’s view, it would seem that the PHS can be deemed a data controller in the PrevBOT project. If there are two or more data controllers, they may be joint data controllers under the GDPR Article 26. If any of the actors are deemed to be data processors, a data processor agreement must be entered into with them.
About the disclosure of personal data from the police
The personal data (chat logs) in PrevBOT were originally collected by the police for the purpose of investigation. When the police make personal data available for processing in the PrevBOT project, the police must have a legal basis for such disclosure. We have not considered disclosure of this kind, as this processing activity falls outside the scope of the PrevBOT project.
We emphasise, nonetheless, that the assumptions mentioned in Chapter 5 (Legal: General information about the police’s processing of personal data for the development of AI) that apply to ‘the entity that discloses/makes personal data available’ must be in place. The Data Protection Authority will also make some comments regarding the compatibility assessment in the context of further processing for use in research.
Compatible further processing
The compatibility assessment applies to information that the data controller already has. When the chat logs are made available to the PrevBOT project for use in research, this is considered the processing of personal data for ‘secondary purposes’. By ‘secondary purposes’ is meant the types of purposes specified in the GDPR, including ‘purposes related to scientific research’, cf. Article 5 (1)(b). Research for a secondary purpose is considered a compatible purpose, cf. the GDPR Article 6(4), provided that the necessary safeguards in accordance with the GDPR Article 89 are in place. This means that the personal data can be processed for this purpose, provided that such safeguards exist.
In the view of the Data Protection Authority, the processing activities set out above will have the same purposes, i.e. purposes related to scientific research. However, it follows from the preparatory work to the Personal Data Act that if further processing for research purposes entails data being disclosed to other data controllers, the data controller receiving the personal data must be able to demonstrate an independent basis for processing.
Legal basis for research
All use of personal data must have a basis for processing for it to be lawful. The GDPR does not establish any specific bases for processing for research purposes, which means that it is the general processing bases in the GDPR Article 6 that are applicable. Several bases for processing may be relevant for research purposes, but for the PrevBOT project, the Data Protection Authority considers Article 6 (1)(e) to be of particular relevance. The provision covers, among other things, the processing of personal data that is ‘necessary for the performance of a task carried out in the public interest’.
The GDPR does not provide any guidelines on what is to be deemed a task in the public interest. The Norwegian commentary to the GDPR assumes ‘that it is not up to each Member State to define what constitutes a task of public interest, but that a common European standard will be developed over time in this area’.
The necessity requirement sets the framework for what constitutes lawful processing of personal data. It is the specific processing of personal data that must be necessary for the performance of a task in the public interest. Relevant aspects to assess include whether the task in the public interest can be fulfilled through less intrusive processing, and whether the processing goes further than the task requires. The European Data Protection Board (EDPB) has stated the following in its guidelines:
Assessing what is ‘necessary’ involves a combined, fact-based assessment of the processing ‘for the objective pursued and of whether it is less intrusive compared to other options for achieving the same goal’. If there are realistic, less intrusive alternatives, the processing is not ‘necessary’.
The Data Protection Authority does not consider an in-depth assessment necessary here, as it seems fairly evident that the processing of personal data within the framework of the PrevBOT project meets the conditions set out in Article 6(1)(e).
Processing of special categories of personal data
Article 9(1) sets out a general prohibition on processing special categories of personal data. The processing of special categories of personal data requires a basis for processing pursuant to the GDPR Article 6. One of the exceptions listed in Article 9(2) must also apply.
Information about a person’s sexual relations is considered a special category of personal data pursuant to Article 9(1). The Data Protection Authority assumes that when personal data is to be processed in the PrevBOT project, it will often fall under the special categories in Article 9. If special categories of personal data are processed, it will be relevant to consider the GDPR Article 9(2)(j).
This provision stipulates several conditions:
- The processing is necessary for the purposes of scientific research in accordance with the GDPR Article 89(1).
- Supplementary legal bases are required (see more on this below).
- The processing must also be proportionate to the aim pursued, respect the essence of the right to data protection and provide for suitable and specific measures to safeguard the fundamental rights and the interests of the data subject. Whether these conditions are met is based on a specific assessment.
Supplementary legal basis
Processing personal data pursuant to the GDPR Article 6(1)(e) and Article 9(2)(j) requires a supplementary legal basis, which means that the basis for the processing in the provisions is ‘determined’ by Union or Member State law. This also follows from Article 6(3) concerning detailed requirements for the wording of legislation, for example, that the purpose should be stated, the type of information registered, affected data subjects and rules for further processing etc. It must be considered specifically how precise the supplementary legal basis should be.
When special categories of personal data are processed, the principle of legality will play a more significant role, where, among other things, gradually stricter requirements will apply to the formulation of the legal authority in the supplementary legal basis.
In the context of the PrevBOT project, three potential supplementary legal bases will be presented.
1. Sections 8 and 9 of the Personal Data Act
In Norwegian law, there is little specific regulation of research, except in the area of health research, and no specific legal authority for research is set out in the Police Databases Act. We must therefore take into account the general supplementary legal bases for research set out in Sections 8 and 9 of the Personal Data Act. The purpose of Sections 8 and 9 is to provide a supplementary legal basis for research where no other supplementary legal basis exists in special legislation.
The provision in Section 8 sets out several conditions. Firstly, the research must be for scientific research purposes. Reference is made to the discussion above, and the Data Protection Authority considers the processing of personal data in PrevBOT to meet this condition.
Furthermore, the processing must be necessary. In the legal commentary on the legal resources website Juridika, the necessity condition here is assumed to have no independent meaning, besides the necessity condition in the GDPR Article 6(1)(e). As long as the condition in Article 6 is met, it will also be met in accordance with Section 8 of the Personal Data Act.
Section 8 of the Personal Data Act
The provision applies to the processing of personal data for purposes related to scientific research and states that:
Personal data may be processed on the basis of Article 6(1)(e) of the General Data Protection Regulation if it is necessary for (...) purposes related to scientific or historical research (...). The processing shall be subject to the necessary safeguards in line with Article 89(1) of the General Data Protection Regulation.
In addition, there is a requirement that the processing be subject to the necessary safeguards in accordance with the GDPR Article 89(1). What constitutes ‘necessary safeguards’ is not stated in the GDPR, but the provision sets out examples of measures that can be taken to ensure the rights and freedoms of the data subject. Among other things, technical and organisational measures must be implemented to ensure compliance with the principle of data minimisation. Such measures may include pseudonymisation, encryption, strict access management, dates of erasure etc.
Several such measures have already been implemented in the PrevBOT project. For example, the Police IT Unit (PIT) restricts access to chat logs made available by local police districts, and personal data must be removed from chat logs before they are made available to CAIR/UiA. However, the Data Protection Authority encourages the data controller to consider whether other measures may also be relevant, relating to the various processing activities in the project.
If special categories of personal data are processed in the PrevBOT project, the stricter conditions in Section 9 must be met. Pursuant to Section 9, there is also a requirement that ‘the interest of society in processing the data clearly outweighs the disadvantages for the individual’.
Section 9 of the Personal Data Act
The provision applies to the processing of special categories of personal data for purposes related to scientific research and states, inter alia, that:
Personal data as mentioned in Article 9(1) of the General Data Protection Regulation may be processed without consent from the data subject if the processing is necessary for (...) purposes related to scientific or historical research (...) and the public interest in the processing taking place clearly outweighs the disadvantages for the individual. The processing shall be subject to the necessary safeguards in line with Article 89(1) of the General Data Protection Regulation 1.
It can be noted that the wording ‘clearly outweighs’ indicates that the threshold is high, and there must be a clear preponderance of interest. The wording here differs slightly from the wording in Article 9(2)(j), which states that it must be ‘proportionate to’. The question is therefore whether the public interest in personal data being processed in the PrevBOT project clearly outweighs the disadvantages for the data subjects whose personal data will be processed in the research (here: the aggrieved, the perpetrator and any third parties mentioned in the chat logs).
Digital abuse of children is clearly a serious criminal act, which many have designated a public health problem. This demonstrates that society has a clear interest in conducting research on means of preventing such crime, such as PrevBOT. At the same time, the specific disadvantages for the data subjects must be thoroughly assessed, especially in relation to the safeguards implemented to limit privacy disadvantages for the data subject.
For the processing of personal data pursuant to Section 9 of the Personal Data Act, the PHS must first consult the data protection officer or other person who meets the requirements of the General Data Protection Regulation Article 37(5)(6) and Article 38(3) first paragraph and second sentence, cf. Section 9 second paragraph. Such consultations must consider whether the processing will meet the requirements of the GDPR and other provisions laid down in or pursuant to law. However, the duty of consultation does not apply if a data protection impact assessment has been carried out pursuant to the GDPR Article 35. The Data Protection Authority emphasises here that all data protection impact assessments (DPIAs) must be submitted to the Data Protection Officer, so that an assessment is always available.
On a general basis, the Data Protection Authority considers the provisions in Sections 8 and 9 to be somewhat unclear compared to the requirements made of how precise the supplementary legal basis should be. A weakness in Section 9 is that it is up to the Data Protection Officer, or similar, to carry out an internal assessment to clarify whether research is lawful. The Data Protection Authority therefore believes that separate research bases should be specified in special legislation that clearly sets out the framework for the research.
In summary, the processing of personal data in the PrevBOT project may meet the requirement for a supplementary legal basis, as long as the conditions in Section 8 (and Section 9 if special categories are processed) of the Personal Data Act, cf. Article 6(1)(e) (and Article 9(1)(j) if special categories are processed) are met.
2. Decisions under the Police Databases Act
There is no specific legal authority in the Police Databases Act for conducting research based on criminal case data. The right to waive the duty of secrecy in Section 33 of the Police Databases Act for information utilised for research does not in itself provide a legal basis for processing the data in such research. It follows from Section 33(2) that the decision-making authority for waiving the duty of secrecy for criminal cases is assigned to the Director of Public Prosecution.
In the area of health research, the Ministry has assumed in the preparatory work to the Personal Data Act that statutory decisions on exceptions to or exemptions from the duty of secrecy may provide supplementary legal grounds pursuant to Article 6(3)
Police Databases Act Section 33(1)
When it is reasonable and does not cause a disproportionate disadvantage for other interests, it may be decided that information in each case is given for use in research, without prejudice to the duty of secrecy in section 23.
Since the Police Databases Act has a similar provision on exemption from the duty of secrecy for research, it can be questioned whether a decision pursuant to Section 33 of the Police Databases Act could constitute a supplementary legal basis pursuant to the GDPR Article 6(3). This is based on a specific assessment of whether the basis for the decision is sufficiently clear in conjunction with the processing that is carried out. The more intrusive the processing, the clearer the supplementary legal basis must be.
In a letter of 27 July 2021, the Director of Public Prosecutions agreed to a special investigator in Trøndelag Police District being granted access to chat logs in criminal cases concerning sexual abuse of children, cf. the Police Databases Act Section 33. The exemption from the duty of secrecy applies to the Nettprat project, which preceded the PrevBOT project, and the Director of Public Prosecutions has subsequently consented to transferring relevant chat logs to PIT in connection with the PrevBOT project.
On the one hand, it may be argued that when an external public body, such as the Director of Public Prosecutions, decides that the duty of secrecy can be waived for research purposes, this will provide some safeguards for the processing of personal data. For example, the Director of Public Prosecutions may require that decisions set out certain measures to ensure the rights and freedoms of the data subject in the processing, following an assessment and weighing of the benefits of the processing and the consequences for the data subjects. It also follows from Section 33 of the Police Databases Act that the provision is limited to cases relating to research. The provision on which the decision is based therefore defines a group of purposes that the data can be used for (research).
On the other hand, the statements in the preparatory work to the Personal Data Act argue that the legislator’s assessment is specific to the field of health research. The Data Protection Authority is not aware of the legislator expressing this opinion with respect to Section 33 of the Police Databases Act, although the Ministry in the aforementioned preparatory works recognises that ‘processing may also take place on other grounds, such as exceptions or exemption decisions under other provisions’. Whether this statement refers only to exceptions/decisions in the health field, or whether it also has transfer value to other areas, is uncertain.
Another point is that health research is subject to relatively strict legislation through the Health Research Act. The same is not the case for other research, where it is often only the general data protection rules, and research ethics in general, that set the framework for the processing of personal data.
Thus, there are several arguments for and against decisions pursuant to Section 33 of the Police Databases Act constituting a supplementary legal basis pursuant to the GDPR Article 6(3) and Article 9(2)(j).
3. New legal authority
It may be questioned whether a possible extension of the scope of the Police Databases Act to include the processing of information for the development of artificial intelligence for police purposes will mean that such processing will then only be regulated by the Police Databases Act. The Data Protection Authority is in doubt about whether any regulatory or legislative changes could lead to the processing falling outside the scope of the GDPR. Such a change will probably not, in the view of the Data Protection Authority, affect the exemption in the GDPR Article 2(2)(d).
However, a statutory provision/regulation in special legislation may provide a supplementary basis under the GDPR. This must be taken into account when formulating the legal authority to ensure that the requirements of Article 6(2) and (3) are met.
Processing of personal data relating to criminal convictions and offences
Information about criminal convictions and offences is not regarded as special categories of personal data, but the processing of such data is specifically referred to in Section 11 of the Personal Data Act and Article 10 of the GDPR. It is natural to interpret ‘criminal convictions and offences’ under these provisions to include information associated with a specific judgment, but also information about criminal acts where a judgment has not been reached at the time of processing.
The processing of such data is subject to certain restrictions, which follow from the GDPR Article 10. In particular, such data may only be processed under supervision of a public authority, or, if the processing is carried out by private persons, provided that there is a basis for processing pursuant to the GDPR Article 6 and a supplementary legal basis.
It is debatable whether the PHS as a research institution is subject to supervision of a public authority, but there may be additional legal bases nevertheless, cf. Section 11 of the Personal Data Act. The provision allows, albeit in a rather complicated manner, processing for research without consent if the public interest in the processing being carried out clearly exceeds the disadvantages for the individual, referencing Section 9 of the Personal Data Act.
For processing pursuant to Section 11 of the Personal Data Act, the PHS must first consult the data protection officer to determine whether the processing will meet the requirements of the GDPR and other provisions set out in or pursuant to the law. However, the duty of consultation does not apply if a data protection impact assessment has been carried out pursuant to the GDPR Article 35.
Summary
In summary, several GDPR provisions allow, subject to certain conditions, the processing of personal data for the purpose of scientific research, including special categories and personal data relating to criminal convictions and offences.
What rights do data subjects have when their personal data is used for research?
The data subject has several rights under the data protection regulations when their personal data is processed. However, the GDPR contains some specific provisions that apply when personal data is processed for purposes related to scientific research. These specific provisions are set out in Section 17 of the Personal Data Act and restrict the general rights of the data subject. The restrictions are only applicable provided there are sufficient safeguards pursuant to the GDPR Article 89(1).
In the following, we will address some key rights regarding the disclosure and processing of personal data for research:
- The right to information gives the data subject, among other things, the right to information about who receives personal data, who the data controller is, the purpose and the legal basis for the processing, unless this proves impossible or would require a disproportionate effort, cf. the GDPR Article 14(1), (2) and (5)(b). Considerations for the impact of the intervention for the individual and the research project must be weighed against each other here. There will be strong incentives in favour of the duty to provide information due to the nature of the information and the fact that neither the aggrieved, the perpetrator nor a third person has provided the information voluntarily. If providing information is considered impossible or would require a disproportionate effort, the controller must take appropriate measures to protect the data subject's rights and freedoms and legitimate interests, including making the information publicly available.
- The right of access pursuant to Article 15 of the GDPR does not apply to such processing if providing access would require a disproportionate effort, or the right of access is likely to render it impossible or seriously obstruct such objectives, cf. Section 17 first paragraph of the Personal Data Act. This exception does not apply if the processing has legal effects or direct practical effects for the data subject. If a right of access exists for the specific processing, it is important to include this in the design of the algorithm/AI model.
- For the right to erasure and restriction of processing under the GDPR Articles 16 and 18, the research design must take two factors into account: the right to erasure of the training data and the right to erase data from the trained model if it contains personal data. In research cases, the right to correction/restriction will not apply under the Personal Data Act Section 17 second paragraph if the rights are likely to render it impossible or seriously obstruct the objectives of the processing being achieved. This is based on a specific assessment.
- The right to object to the processing does not apply if the personal data for scientific purposes is processed in accordance with the GDPR Article 6 (1)(e), cf. Article 21(6).