How will PrevBOT work?
‘PrevBOT’ stands for ‘Preventive Robot’, a reference to its preventative purpose and the artificial intelligence implemented in the robot technology.
PrevBOT can be present in chat forums, but in its basic form, it is not a generative chatbot that can participate autonomously in conversations. Whether such an interactive function should be integrated in the future needs to be assessed in relation to, for example, the legal boundaries for infiltration and entrapment as well as ethical considerations. The sandbox process has treated PrevBOT as a passive observation tool, and it is therefore not to be considered a chatbot.
The fundamental feature a PrevBOT requires is the ability to monitor conversations in open online forums and identify, in real time, conversations in which grooming is taking place. By extracting statistics from PrevBOT, the police will also be able to identify places online where there is an increased risk of grooming. The robot should, in other words, be able indicate problematic areas of the internet and point out individuals.
How can grooming be identified?
There are essentially three main internal functions the bot needs to perform:
-
Detect grooming language
The bot must recognise words and phrases relating to sex talk, and not only in the lexical sense. It also needs to remain up to date in terms of slang and code words. With effective and continuous training and updating, it may be able to recognise the signs of a grooming conversation before the language becomes sexually explicit.
-
Detecting fake profiles
The robot must be able to estimate the gender and age of the person chatting. Many abusers pretend to be something other than what they really are (including minors). By estimating gender and age, the robot can detect conversations in which there is a significant difference in age. This will allow PrevBOT to detect whether there are adults in forums in which the other users are young, or vice versa, if a minor gains access to an adult-only chat room.
-
Sentiment analysis
The bot must identify the emotions of the individuals chatting. Response time, typing speed, the language used and writing style can reveal, for example, whether a person is aggressive/persistent/impatient, even if the written content suggests a calm and relaxed demeanour. This can be a sign that a user’s intentions differ from the intentions they express.
The bot does not necessarily have to suspect deception about age/gender and emotion for the conversation to be classified as grooming, but together, these three detections will provide useful input when assessing a conversation.
When PrevBOT classifies a conversation as potential grooming, the conversation is flagged. At that point, the idea is that humans take over and decide whether or not there are grounds for intervention and how it should be implemented. In other words, PrevBOT is intended as a decision support tool.
The manner in which the police intervene in flagged conversations has not been determined. The original idea of the project was that the groomer somehow receives a warning and the grooming attempt is somehow intercepted. The police already have online patrols that monitor and have experience in such areas and the hope is that PrevBOT will serve to increase their capacity.
The sandbox project has discussed whether it would be just as effective if the ‘victim’ also received a message, or the possibility that only the ‘victim’ receives a warning. For a vulnerable minor, it may be disconcerting for a conversation to be suddenly ended without explanation. We did not conclude what would work best but recommend that the PrevBOT project test the alternatives – and at any rate take into account the ‘victims’ – when determining the manner in which grooming attempts are intercepted.
Detecting sexualised language
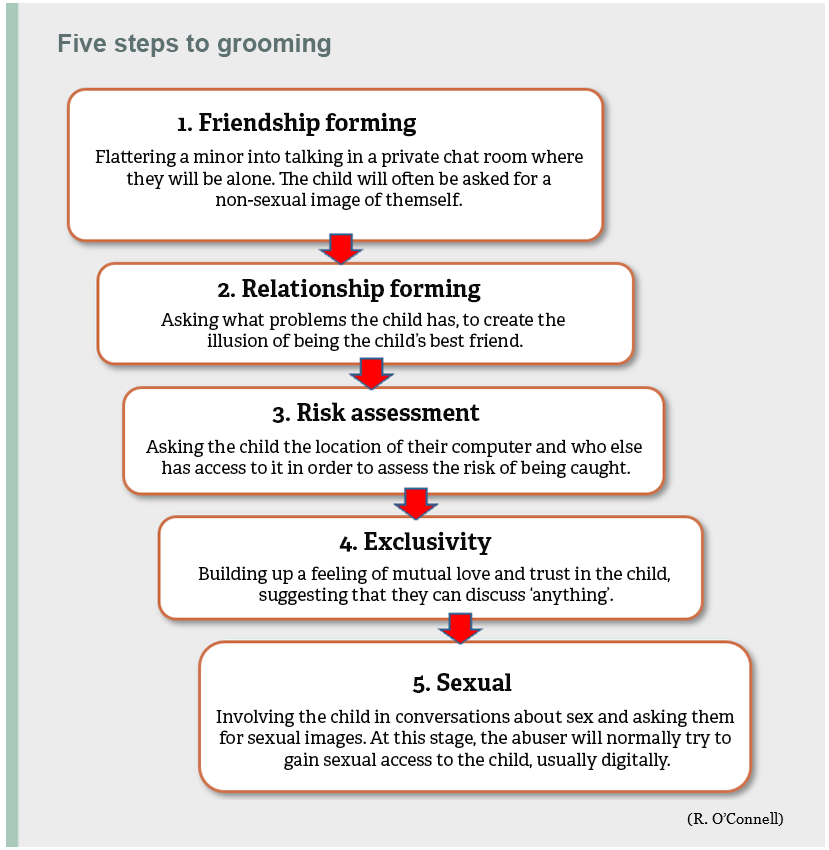
A significant amount of research has been conducted internationally on grooming linguistics. Many of the studies are based on R. OʼConnellʼs five-step model of online grooming processes. As the model indicates, it may only be in the fifth step that the conversation becomes explicitly sexual. However, it is possible to recognise grooming attempts during the previous four steps. The Risk Assessment step can be particularly revealing. Recent research suggests that online groomers are now more impatient, perhaps cautious, and carry out risk assessment at an earlier stage of the process.
With machine learning (ML), natural language processing (NLP) and neural networks, models can be trained to recognise the signs of a grooming conversation. They are trained using reference data from conversation logs in which grooming was retrospectively found to have occurred.
Stylometry is the study and analysis of linguistic style and writing patterns that allows vocabulary, sentence lengths, word frequency and all other quantifiable text characteristics to be evaluated. For example, it may be interesting to see how often a question is asked in a conversation. Researchers Borj and Bours at the Norwegian University of Science and Technology (NTNU) have had promising results in their attempts to recognise grooming conversations. Using various classification techniques, they succeeded in detecting abusers with up to 98 per cent accuracy.
Detecting deception
Author profiling involves analysing texts to identify an author’s gender, age, native language, personality traits, emotions and similar characteristics. Experiments show that such profiling can be impressively accurate, especially if the categories are broad – e.g. is the writer a child (under the age of 18) or an adult (for example, over the age of 25) – and if the model is trained in specific topics (e.g. chat room conversations) rather than a broader range of areas.
If the person chatting in the text or writing a user profile pretends to be something other than the categories they are assigned by author profiling, it may indicate that grooming is underway.
Interpreting emotions
Sentiment analysis uses NLP and machine learning techniques to identify and extract subjective information from text data. Sentiment analysis uses artificial intelligence that reads what is written and sorts text into categories of sentiment. A simple example would be a company that monitors how its products are reviewed. Such an analysis can categorise text as ‘positive’, ‘negative’ or ‘neutral’, or sort text to an even more granular level.
Sentiment analysis is used in many different areas. The entertainment industry uses it to measure audience reactions to TV series when assessing whether to conclude or extend a production. In politics, it is used to analyse people’s reactions to political initiatives and events, and in the financial sector, it is used to capture trends in the financial market.
The above examples relate to group-level sentiment analysis, but it can also be used at an individual level. The same methods are used when social media platforms track your activity – what you like, what you comment on, what you post and where you stop when scrolling. The better they know your emotional life, the more effectively they can target you with ads and content.
Keystroke biometrics
Today’s technology can do more than just categorise an author, such as with author profiling, and identify the author’s true emotions. It can actually identify an individual author using keystroke biometrics, based on the idea that an individual’s use of language is so unique that it is like a textual fingerprint. There is a preliminary plan to include this feature in PrevBOT, providing it with the ability to recognise previously convicted sex offenders who have become active again online. This feature has not been discussed in the sandbox project, however.
Explainable Tsetlin
The PHS envisages building PrevBOT on a Tsetlin machine (TM). The benefit of a Tsetlin machine is that it has a higher level of explainability than neural networks. In a project like PrevBOT, where people are to be categorised as potential abusers based on (in most cases) open, lawful, online communication, it will be important to be able to understand why the tool reaches its conclusions.
A detailed description of the Tsetlin machine can be found in Chapter 6 of this report.
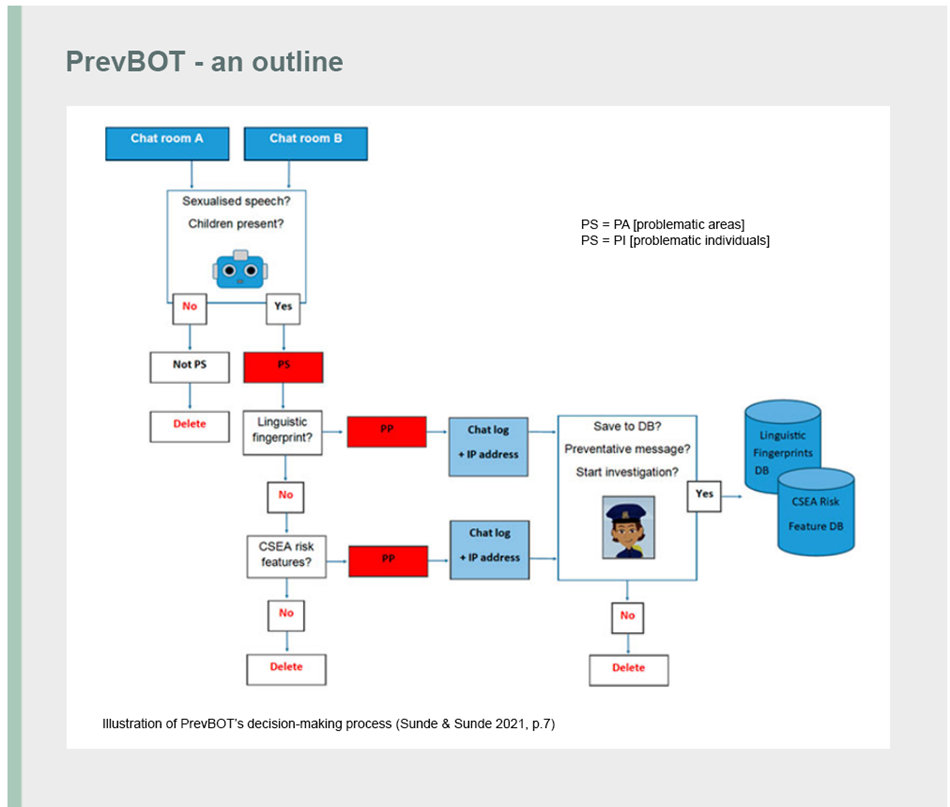
The figure above illustrates PrevBOT’s decision-making process. PA stands for problematic areas, while PI stands for problematic individuals. The illustration is taken from Sunde & Sunde’s article from 2021. The discussions in the sandbox have assumed that the capability of tracing textual fingerprints will not be included as a feature in PrevBOT.
Starting an investigation is given as an alternative in the figure, but the PrevBOT project has stated that the option to start an investigation would be most relevant in conjunction with the keystroke biometrics function, which is no longer applicable.