Generelle krav til rettslig grunnlag
Personvernforordningen (GDPR) krever at all behandling av personopplysninger har hjemmel i ett av de seks rettslige grunnlagene oppstilt i artikkel 6 nr. 1 bokstav a til f.
Hva er behandling av personopplysninger?
Kort fortalt er personopplysninger alle opplysninger som kan knyttes til en fysisk person, direkte eller indirekte. Det spiller ingen rolle hvilket format opplysningene har. Tekst, bilder, video og lyd er for eksempel omfattet. «Behandling» er alt man gjør med opplysningene, blant annet innsamling, strukturering, endring og analysering.
Artikkel 9 nr. 1 oppstiller et generelt forbud mot å behandle særlige kategorier av personopplysninger. Dette gjelder blant annet helseopplysninger, fordi denne type av personopplysninger anses særlig sensitive i sin natur. Artikkel 9 nr. 2 oppstiller en rekke unntak fra forbudet. Unntakene oppstilt i bestemmelsen er uttømmende.
Generelt om supplerende rettsgrunnlag og legalitetsprinsippet
Både personvernforordningen artikkel 6 nr. 3 og artikkel 9 nr. 2 krever i noen tilfeller et supplerende rettsgrunnlag i nasjonal lovgivning. Dette innebærer at den dataansvarlige må kunne påvise et rettslig grunnlag for den aktuelle behandlingen av personopplysninger både i personvernforordningen og i nasjonal rett.
Dataansvarlig
«Dataansvarlig» er et begrep som benyttes i helselovgivningen for den som er å anse som behandlingsansvarlig i personvernforordningens forstand. Personvernforordningen artikkel 4 nr. 7 definerer dette som:
«en fysisk eller juridisk person, en offentlig myndighet, en institusjon eller ethvert annet organ som alene eller sammen med andre bestemmer formålet med behandlingen av personopplysninger og hvilke midler som skal benyttes».
Et spørsmål er også hvor klart det supplerende rettsgrunnlaget må være. Artikkel 6 nr. 3 kan gi en viss veiledning når lovgiver skal utforme et slikt rettsgrunnlag. Bestemmelsen presiserer blant annet at det ikke stilles krav til en spesifikk lovbestemmelse for hver enkelt behandling så lenge formålet med behandlingen er fastsatt i nasjonal lov, eller formålet er nødvendig for å utøve offentlig myndighet. Som vi skal se nærmere på i det følgende vil både bokstav c og e være relevante rettsgrunnlag for utviklingen og bruken av algoritmen til Helse Bergen.
Forarbeidene til personopplysningsloven presiserer at behandling på grunnlag av artikkel 6 nr. 1 bokstav c må ha et supplerende rettsgrunnlag, der formålet er fastsatt i rettsgrunnlaget. Det er imidlertid tilstrekkelig at det supplerende rettsgrunnlaget pålegger dataansvarlig en rettslig forpliktelse som det krever behandling av personopplysninger for å oppfylle.
Se Prop. 56 LS (2017-2018) punkt 6.3.2 på regjeringen.no (pdf)
For artikkel 6 nr. 1 bokstav e er det tilstrekkelig at det er nødvendig for dataansvarlig å behandle personopplysninger for å utøve myndigheten som følger av det supplerende rettsgrunnlaget. Det supplerende rettsgrunnlaget trenger altså ikke å uttrykkelig regulere selve behandlingen av personopplysninger.
Finnes det et rettslig grunnlag for å bruke personopplysninger til å utvikle og bruke KI i klinikk?
For den videre fremstillingen er det naturlig å dele spørsmålet om rettslig grunnlag inn i algoritmemodellens to hovedfaser, (1) beslutningsstøtteverktøyets utviklings- og etterlæringsfase og (2) anvendelsesfasen der algoritmemodellen brukes i klinikk.
(1) Rettslig grunnlag for utviklings- og etterlæringsfasen
Utviklingen av algoritmen er basert på historiske helseopplysninger fra nærmere 200 000 pasienter ved Helse Bergen HF i tidsrommet 2018 til 2021. Dette innebærer at helseopplysninger som er samlet inn om én pasient benyttes til formål om å gi helsehjelp til andre, utover denne ene pasienten. Etterlæringsfasen innebærer å kontinuerlig tilføre algoritmen nye helseopplysninger slik at algoritmen til enhver tid er oppdatert og utvikler seg i takt med endringer som oppstår. Behandlingen av helseopplysninger i utviklings- og etterlæringsfasen krever et rettslig grunnlag i personvernforordningen og nasjonal rett.

Personvernforordningen artikkel 6 nr. 1 bokstav e oppstiller krav om at behandlingen er «nødvendig» for å utføre en «oppgave i allmennhetens interesse» eller «utøve offentlig myndighet som den behandlingsansvarlige er pålagt». Formålet med utviklingen av algoritmen er å redusere antall reinnleggelser, forbedre oppfølging av pasienter og effektivisere ressursbruk i helsesektoren.
Artikkel 9 nr. 2 bokstav h kan gjøre seg gjeldende der behandlingen av personopplysninger er «nødvendig» i forbindelse med «forebyggende medisin» eller i forbindelse med «yting av helse- eller sosialtjenester, behandling eller forvaltning av helse- eller sosialtjenester og -systemer». For behandling av helseopplysninger vil også artikkel 9 nr. 2 bokstav i kunne benyttes når det er «nødvendig av allmenne folkehelsehensyn». Begrepet «allmenne folkehensyn» er ikke nærmere definert, men det eksemplifiseres blant annet med at det omfatter å «sikre høye kvalitets- og sikkerhetsstandarder for helsetjenester og legemidler eller medisinsk utstyr». Bokstav i kan være naturlig å bruke eksempelvis ved intern kvalitetssikring av modellen i produksjon (etterlæringsfasen).
Artikkel 6 nr. 3 og artikkel 9 nr. 2 bokstav h og i oppstiller krav om at behandlingen av helseopplysninger i tillegg må ha supplerende rettsgrunnlag i nasjonal rett.
Supplerende rettsgrunnlag i helselovgivningen
Utgangspunktet for all behandling av helseopplysninger i helsetjenesten er at helsepersonell er underlagt taushetsplikt, jf. helsepersonelloven § 21 og pasientjournalloven § 15. Taushetsplikten skal sikre pasienters grunnleggende rett til privatliv og ivareta tilliten til helsetjenestene. Alle unntak fra taushetsplikten krever at pasienten samtykker, eller at unntaket har hjemmel i lov.
Et typisk og praktisk unntak fra taushetsplikten er at opplysninger kan deles med annet helsepersonell når det er «nødvendig» for å yte «forsvarlig helsehjelp», jf. helsepersonelloven §§ 25 og 45. Tilsvarende kreves det hjemmel i lov for å benytte helseopplysninger om en pasient til utvikling av en algoritme som skal brukes i helsehjelpen til andre pasienter. Som følge av at det ikke er særlig praktisk å innhente samtykke fra hver enkelt pasient for å oppheve taushetsplikten, må en slik sekundærbruk av helsedata omfattes av et lovfestet unntak fra taushetsplikten.
Helsepersonelloven § 29, som trådte i kraft sommeren 2021, oppstiller en dispensasjon fra taushetsplikten for tilgjengeliggjøring av opplysninger fra pasientjournaler og andre behandlingsrettede helseregistre.
På særskilte vilkår, og etter søknad, kan bestemmelsen benyttes som et rettslig grunnlag for utvikling og etterlæring av beslutningsstøtteverktøy med kunstig intelligens, jf. første ledd bokstav a:
Helsepersonelloven § 29
«Departementet kan etter søknad bestemme at opplysninger fra pasientjournaler og andre behandlingsrettede helseregistre skal tilgjengeliggjøres uten hinder av taushetsplikt etter § 21, når
a.) opplysningene skal brukes til et uttrykkelig angitt formål knyttet til statistikk, helseanalyser, forskning, utvikling og bruk av klinisk beslutningsstøtteverktøy, kvalitetsforbedring, planlegging, styring eller beredskap for å fremme helse, forebygge sykdom og skade eller gi bedre helse- og omsorgstjenester.»
(vår utheving)
I forarbeidene uttaler Helse- og omsorgsdepartementet at:
«Det skal gjøres en konkret vurdering der samfunnsnytten skal veies opp mot personvernulempene for den enkelte. Hensynene bak taushetsplikten og pasientens rett til vern mot spredning av opplysninger skal veie tungt.»
Se Prop. 63 L (2019-2020), kapittel 16.1 på side 129 (pdf)
For å sikre at datagrunnlaget til enhver tid er representativt, må modellen kontinuerlig tilføres nye helseopplysninger. En slik etterlæring av algoritmen kan ha hjemmel i helsepersonelloven § 29, jf. ordlyden «utvikling».
Ved behandling av helseopplysninger for internkontroll og kvalitetssikring, er det naturlig å benytte helsepersonelloven § 26 som hjemmelsgrunnlag og unntak fra taushetsplikten. Kvalitetsforbedring forstås i denne sammenhengen som en kontroll av om algoritmen er forsvarlig når den anvendes i klinikk.
Innføring av helsepersonelloven § 29 sommeren 2021 kan ses på som et signal om at myndighetene ønsker å tilrettelegge for økt bruk av kunstig intelligens i klinisk helsetjeneste. Det er Helsedirektoratet som er aktuell myndighet for behandling av søknader om dispensasjon.
(2) Rettslig grunnlag for anvendelsesfasen
I denne fasen brukes beslutningsverktøyet som en del av det kliniske helsetilbudet. I begrepet «klinisk» ligger at formålet med utviklingen av verktøyet skal være ytelse av helsehjelp og praktisk medisin. Algoritmen vil analysere den enkeltes pasientdata og gi en skåring av pasientens sannsynlighet for reinnleggelse i fremtiden. Deretter vil en software-robot klippe ut skåringen som er generert av algoritmen og lime dette inn i pasientjournalsystemet DIPS, slik at det blir tilgjengelig for behandlende lege.
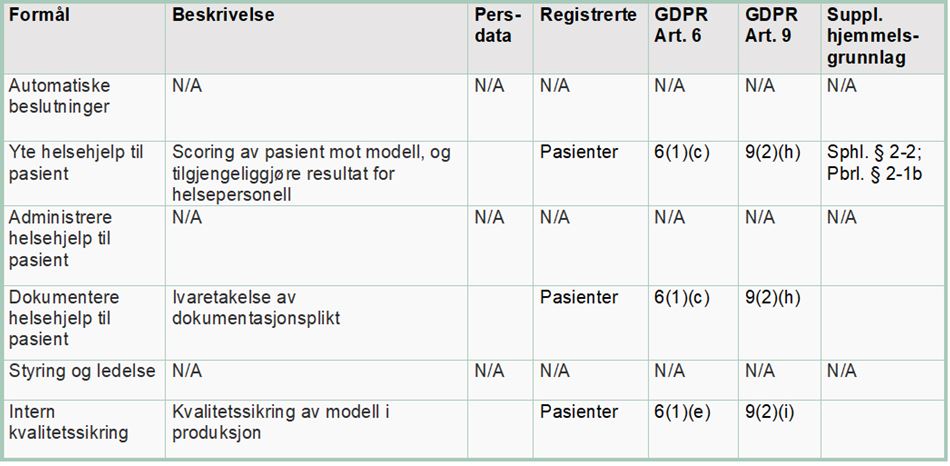
Ved bruk av den enkelte pasients helseopplysninger, vil algoritmen gi en prediksjon for hvilken risiko pasienten har for å bli reinnlagt i fremtiden. Helseforetak har en plikt til å yte forsvarlige helse- og omsorgstjenester og må i den forbindelse behandle opplysninger som anses nødvendige og relevante for ytelsen av disse tjenestene. For denne behandlingen av personopplysninger er det aktuelt å se nærmere på artikkel 6. nr. 1 bokstav c, som krever at:
«Behandlingen er nødvendig for å oppfylle en rettslig forpliktelse som påhviler den behandlingsansvarlige.»
Som følge av at beslutningsstøttesystemet behandler helseopplysninger om pasienten, må et av unntakene i artikkel 9 nr. 2 komme til anvendelse for at behandlingen skal være lovlig. Bokstav h oppstiller en adgang til å behandle helseopplysninger dersom behandlingen er «nødvendig» i forbindelse med «forebyggende medisin» eller i forbindelse med «yting av helse- eller sosialtjenester».
Supplerende rettsgrunnlag i norsk rett finner vi blant annet i spesialisthelsetjenesteloven § 2-2, jf. § 2-1, som pålegger spesialisthelsetjenesten å yte forsvarlige helsetjenester til borgerne:
«Helsetjenester som tilbys eller ytes i henhold til denne loven skal være forsvarlige. Spesialisthelsetjenesten skal tilrettelegge sine tjenester slik at personell som utfører tjenestene, blir i stand til å overholde sine lovpålagte plikter, og slik at den enkelte pasient eller bruker gis et helhetlig og koordinert tjenestetilbud.»
Forsvarlighetsplikten er en rettslig standard i helselovgivningen. En rettslig standard er dynamisk og vil utvikle seg i takt med samfunnsutviklingen og nye standarder for helsehjelp. Dette skaper mindre forutsigbarhet for pasienten. Tilgang til og behandling av personopplysninger er likevel en forutsetning for, og en naturlig del av, plikten til å yte forsvarlig helsehjelp. Ifølge forarbeidene til helsepersonelloven, der kravet til forsvarlighet er omtalt, skal innholdet i forsvarlighetsplikten vurderes ut ifra legitime forventninger, helsepersonellets kvalifikasjoner, arbeidets karakter og situasjonen for øvrig.
Se Ot.prp.nr.13 (1998-99) punkt 4.2.5.3 på regjeringen.no
Helsepersonellets forsvarlighetsplikt gjelder uavhengig av pasientens frivillighet og mulighet til å ivareta egen autonomi. Forsvarlighetskravet kan forstås som en plikt til å utvikle og tilby helsetjenester basert på ny kunnskap og teknologi, også ved bruk av kunstig intelligens der det er forventet nytteverdi.
I helsepersonelloven § 39 oppstilles det videre en dokumentasjonsplikt for den som yter helsehjelp. Denne plikten innebærer en individuell plikt til å nedtegne opplysninger om pasienten og helsehjelpen som er relevante og nødvendige, se også pasientjournalloven § 40 og forskrift om pasientjournal. Dokumentasjonsplikten er begrunnet i forsvarlighetsplikten.
Dersom det skal behandles ytterligere opplysninger enn det som anses nødvendig og relevant for ytelse av helse- og omsorgstjenester og helsepersonellets dokumentasjonsplikt i det konkrete tilfelle, må det foreligge et eget rettslig grunnlag.
Videre oppstiller pasientjournalloven § 19 en plikt for helsevirksomheten til å:
«sørge for at relevante og nødvendige helseopplysninger er tilgjengelige for helsepersonell og annet samarbeidende personell når dette er nødvendig for å yte, administrere eller kvalitetssikre helsehjelp til den enkelte.»
Bestemmelsen kan benyttes som rettsgrunnlag så langt behandlingen av opplysningene som behandles er nødvendige og relevante for tjenesteytelsen.
Retten og plikten til å dele pasientopplysninger med samarbeidende personell fremgår også av helsepersonelloven §§ 25 og 45.
Som en oppsummering, finnes det flere lovbestemmelser i helselovgivningen som gir adgang til å benytte personopplysninger i pasientbehandling, (se særlig spesialisthelsetjenesten § 2-2 og pasientjournalloven § 19). En grunnleggende forutsetning for at helsepersonell skal være i stand til å yte forsvarlig helsehjelp, (jf. spesialisthelsetjenesten § 2-2), er tilgang til relevante og nødvendige pasientopplysninger.
Forbudet mot automatiserte beslutninger vs. beslutningsstøttesystem
Artikkel 22 i personvernforordningen oppstiller et forbud mot beslutninger som kun er basert på automatisert behandling. For at et slikt forbud skal gjøre seg gjeldende, må det være tale om en beslutning uten menneskelig innblanding, i tillegg til at beslutningen må ha en rettsvirkning eller en betydelig påvirkning på den enkelte pasient. Krav om menneskelig innblanding betyr at beslutningsprosessen må ha innslag av en reell og faktisk vurdering utført av et menneske.
Algoritmemodellen i prosjektet til Helse Bergen HF er begrenset til et beslutningsstøtteverktøy, og det skal bare benyttes som en veiledning for helsepersonell i vurderingen av oppfølging av pasient. I forarbeidene til helsepersonelloven presiseres det at begrepet «beslutningsstøtteverktøy» skal forstås vidt, og det omfatter alle typer kunnskapsbaserte hjelpemidler og støttesystemer som kan gi råd og støtte og veilede helsepersonell ved ytelse av helsehjelp. Det omfatter også utvikling og bruk av systemer som bygger på kunstig fintelling og systemer som bygger på maskinlæring. Anbefalingen fra algoritmen vil på denne måten kun være en av mange faktorer som er avgjørende for hvilke tiltak som iverksettes.
Det må likevel understrekes at det ved bruk av algoritmen i klinisk behandling, skjer en profilering av pasienten, jf. art. 4 nr. 4. Profilering defineres som enhver form for automatisert behandling av personopplysninger som innebærer å bruke personopplysninger for å vurdere visse personlige aspekter knyttet til en fysisk person, særlig for å analysere eller forutsi aspekter ved en fysisk persons arbeidsprestasjoner, økonomiske situasjon, helse, personlige preferanser, interesser, pålitelighet, atferd, plassering eller bevegelser. Selv om ikke profilering alene utløser forbudet i artikkel 22, kan profilering, og særlig profilering som omfatter helseopplysninger, indikere at det foreligger en høy risiko ved behandlingen.
Selv om algoritmen brukes som et beslutningsstøttesystem eksisterer det en risiko for at helsepersonell legger algoritmeresutaltet til grunn uten en selvstendig vurdering. Bruk av KI-verktøyet blir på denne måten i praksis helautomatisert. Tiltak for å redusere risikoen for at dette skjer, er å sørge for tilstrekkelig informasjon og opplæring av helsepersonell før verktøyet tas i bruk, presentasjon av sannsynligheter fremfor kategoriske utfall, åpenhet om verktøyets treffsikkerhet, og innføring av rutiner og kontrollmekanismer for å avdekke feil i modellen.



